Imagine you’re sneaking past digital gatekeepers, slipping through unnoticed - only to be caught because you’re wearing the same disguise every time. That’s exactly what happens when web scrapers don’t use IP rotation Python effectively.
Websites track repeated requests from the same IP, blocking or throttling them. Proxy rotation is the key to staying undetected, making your scraping smoother and more efficient. But how do you implement it in Python?
In this guide, we’ll break down what proxy rotation is, how to rotate proxies using Requests and AIOHTTP, and expert tips to keep your scrapers running stealthily. Ready to level up your proxy game? Let’s dive in!
CTA: Avoid IP bans and unlock seamless data extraction with Proxy-Cheap’s rotating proxy solutions. Whether you need to rotate IP addresses, scrape at scale, or stay anonymous, our fast and affordable proxies ensure smooth and uninterrupted access to any target website.
Sign up today and power up your scraping with the best proxy solutions!

When performing web scraping, sending multiple requests from the same IP address can quickly lead to blocks or rate limits. Websites monitor traffic patterns and may flag repeated requests, restricting access to their data. This is where IP rotation comes into play. Proxy rotation is the process of automatically changing your IP address at regular intervals or for each request, allowing scrapers to bypass anti-scraping measures. By routing traffic through a proxy server, scrapers can appear as if their requests are coming from different locations, making it harder for websites to detect automation.
A proxy rotator helps manage this process by selecting IPs from a proxy list and assigning a new one for each connection. You can use free proxies or paid services to ensure a steady supply of fresh multiple IP addresses, reducing the chances of getting blocked. Python makes it easy to implement proxy rotation using libraries like import requests, enabling scrapers to rotate IP addresses seamlessly. Whether you’re gathering market data, monitoring competitors, or automating research, effective proxy rotation ensures smooth and anonymous data extraction.
Now that we understand the importance of proxy rotation, let's dive into how to implement it in Python. Simply using a single proxy isn't enough - effective IP rotation requires strategic handling to ensure seamless request flow and avoid detection. Whether you're working with import requests for basic setups or leveraging asynchronous frameworks for high-speed scraping, Python offers multiple ways to rotate proxies efficiently.
In this section, we'll walk through the essential steps, from installing prerequisites to setting up a proxy pool and using asynchronous requests for optimal performance. Let’s get started!
Before implementing IP rotation in Python, you need to install essential libraries that help manage proxies, send requests, and handle asynchronous operations efficiently. The two primary libraries are requests, which allows making HTTP requests easily, and aiohttp, which enables asynchronous requests for faster execution. You may also need BeautifulSoup for parsing HTML content and random to shuffle proxy lists dynamically.
To install these dependencies, run the following command:

Additionally, if you’re working with a large target website, using a free proxy list or premium proxy service is crucial to maintaining uninterrupted access. Websites often track users making repeated requests from the same IP, leading to blocks or CAPTCHAs. To avoid this, you should rotate IP addresses by using multiple proxies, ensuring that requests appear as if they are coming from different users.
A well-structured proxy rotation setup should include a reliable list of working IP addresses and an automated mechanism to switch proxies with each request. You can either gather free proxies from public sources or use a paid service for better reliability. To further reduce detection, it's recommended to combine IP rotation with user-agent switching and request delays. In the next section, we’ll start by sending a basic request without proxies to establish a baseline before integrating proxy rotation.
Before implementing proxy rotation, it's essential to understand how a basic request works without proxies. This step helps establish a baseline for web scraping by showing how websites detect and log requests based on your actual IP address. Without using a proxy server, repeated requests from the same IP can lead to blocks, CAPTCHAs, or restricted access, especially on sites with strict anti-scraping measures.
Let’s start by making a simple request using requests in Python:

This script will return your actual IP address, revealing how websites identify and track visitors. If you’re scraping frequently, relying solely on this method can result in access being revoked. That’s where rotate proxies come in - by routing your traffic through a proxy server, you can mask your identity and distribute requests across random proxy IPs.
Since public free proxies often get blocked quickly, using a proxy rotator ensures a steady flow of working proxies. In the next section, we’ll explore how to modify this script to send requests through proxies, making it harder for websites to detect automation.
Now that we’ve established a baseline, let’s configure a single proxy to hide our original IP address when making requests. Using a proxy allows you to bypass restrictions and reduce the chances of getting blocked while scraping data. However, not all proxies are reliable - some may be flagged as a transparent proxy, meaning websites can still see your real IP. To avoid this, it’s best to use valid proxies that ensure anonymity.
Here’s how you can send a request through a proxy in Python:
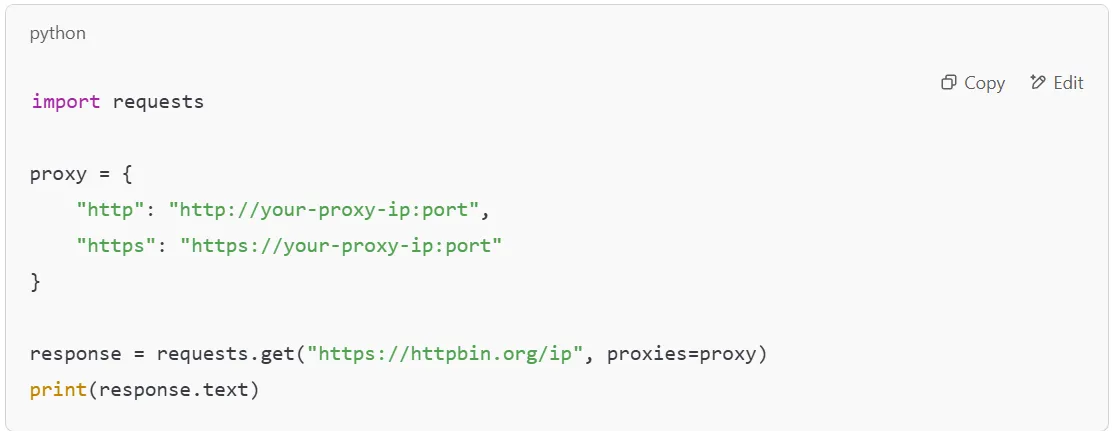
If you’re working with multiple proxies, you can store them in a txt file and load them dynamically. However, manually switching proxies isn’t efficient, which is why many developers rotate proxies in Python for better performance. Services like residential proxies offer high-quality IPs that mimic real user behavior, making them ideal for large-scale scraping. For even better automation, rotating residential proxies can handle proxy rotation for you.
Additionally, combining proxies with user agent rotation - which changes your browser fingerprint - further enhances anonymity. In the next section, we’ll take this a step further by automating proxy switching using a proxy pool.
Using a single IP address for web scraping can quickly get you blocked, especially if the target website has strict anti-bot measures. Instead of manually switching proxies, you can set up a proxy pool, which automatically assigns different IP addresses for each request. This method ensures that no two consecutive requests come from the same source, reducing the chances of detection. Whether you’re using free proxies or premium services, a well-structured proxy pool is essential for efficient scraping.
A proxy pool is simply a collection of multiple proxies that your script can cycle through. You can gather proxies from a free proxy list website, but keep in mind that public proxies often suffer from reliability issues, slow speeds, and frequent bans. For a more stable setup, premium services like Rotating ISP proxies provide high-speed, residential-grade IPs that are less likely to get blacklisted.
Here’s how you can set up a basic proxy pool in Python:
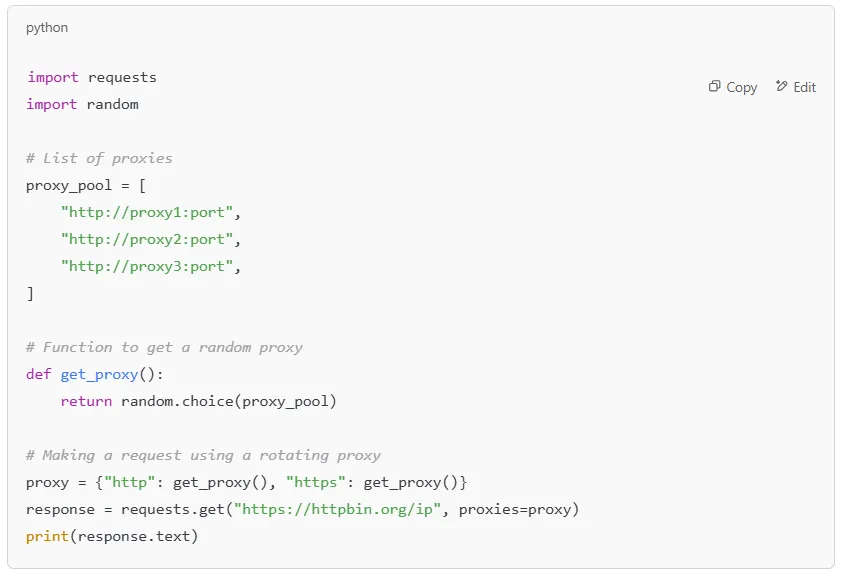
This script randomly selects a proxy from the pool for each request, ensuring that your scraper doesn’t repeatedly hit the server from the same IP address.
When setting up a proxy pool, it's important to understand the difference between a static proxy and a rotating proxy. A static proxy assigns you the same IP for an extended session, which can be useful for maintaining persistent logins or sessions. On the other hand, rotating proxies automatically rotate IP addresses at set intervals, making them ideal for large-scale data extraction. If you’re unsure which to choose, check out this detailed guide on static vs. rotating proxies.
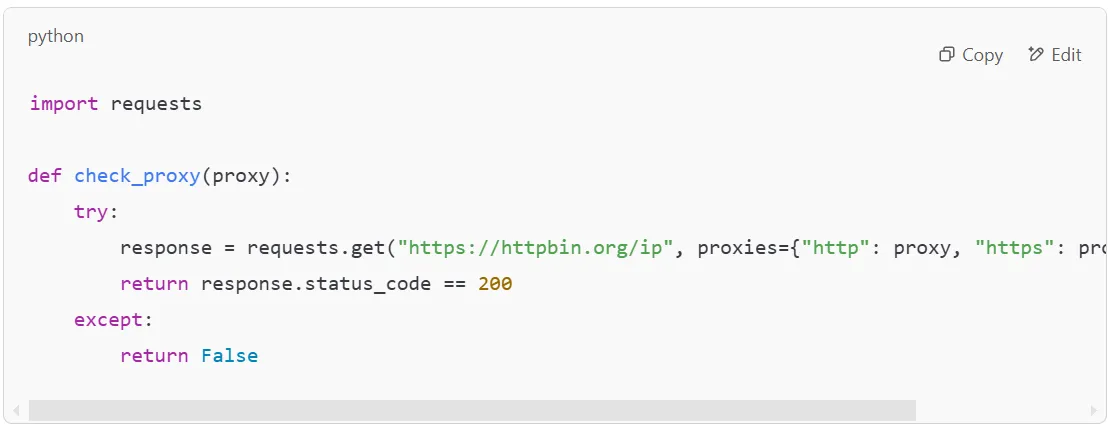
Not all proxies offer full anonymity. Some, like an anonymous proxy, mask your IP address completely, while others, such as an http proxy, may still reveal certain connection details. To maximize anonymity, always test your proxies before use. A simple way to check if your proxy is working correctly is by running:

For long-term scraping projects, relying solely on free proxies can be risky due to their instability. Instead, a paid service that offers automatic proxy rotation ensures continuous access without manual intervention. In the next section, we’ll take automation a step further by using Python’s asynchronous capabilities to manage proxy rotation efficiently.
For large-scale web scraping, sending multiple requests sequentially can be slow and inefficient. Instead, using an asynchronous approach with asyncio and aiohttp allows you to handle multiple connections simultaneously while ensuring efficient proxy rotation. This method is particularly useful when dealing with proxy providers or an elite proxy service to bypass restrictions on a target website.
When making requests to a target website, using a proxy rotator helps to rotate IP addresses and avoid detection. However, traditional synchronous requests can slow down the process significantly, as each request waits for a response before sending the next one. By using asyncio and aiohttp, we can send multiple asynchronous requests at the same time while dynamically switching proxies.
Before implementing the asynchronous method, install the necessary libraries using:

This installs requests (for testing), aiohttp (for asynchronous HTTP requests), and asyncio (to manage concurrency).
Here’s how you can implement proxy rotation using Python’s asyncio and aiohttp:

By combining asyncio, aiohttp, and proxy rotation, you can significantly enhance your web scraping efficiency. While pip install requests is a common first step, moving to an asynchronous approach provides a much-needed speed boost when dealing with large-scale data extraction.
While using proxy rotation is essential for successful web scraping, it’s equally important to follow best practices to maximize efficiency, maintain anonymity, and avoid getting blocked. Here are some key tips to enhance your proxy rotation strategy:
While free proxies may seem appealing, they often come with issues like slow speed, poor uptime, and frequent blacklisting. Investing in premium proxy services such as residential proxies or rotating ISP proxies ensures a reliable connection and better anonymity. High-quality proxies provide clean IP addresses that are less likely to get flagged.
Sending too many requests in a short time, even with rotating proxies, can raise suspicion and lead to bans. Implement random delays between requests to mimic human-like behavior. Using Python’s time.sleep() or asyncio.sleep() can help introduce variability.
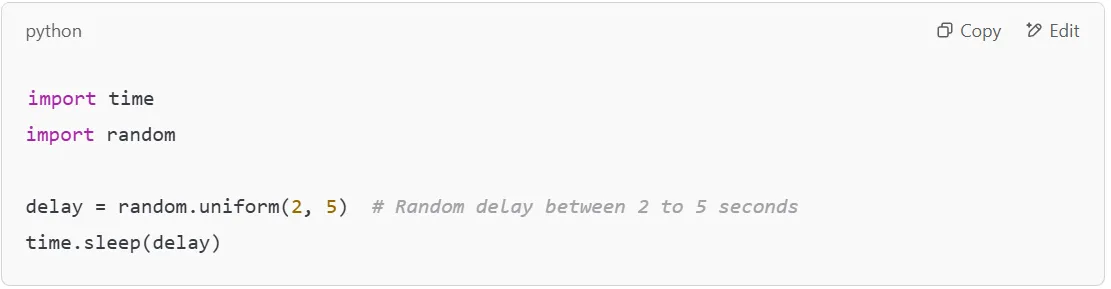
This technique significantly reduces the chances of triggering anti-scraping mechanisms on a target website.
Websites often deploy CAPTCHAs to detect bots. If your scraper frequently encounters CAPTCHAs, consider integrating a CAPTCHA-solving service like 2Captcha or Anti-Captcha. Alternatively, using headless browsers with Selenium or Puppeteer can help bypass detection.
Just like rotating IPs, changing the User-Agent string in HTTP headers makes your scraper appear as different users. Many websites track User-Agent consistency, so combining IP rotation with user agent rotation enhances stealth.

This approach helps avoid detection when making multiple requests.
Not all proxies remain functional indefinitely. Some proxy servers may become slow, get blocked, or fail to connect. It’s crucial to regularly check your proxy pool and remove bad proxies.
Automating proxy health checks ensures your scraper always uses working IP addresses for stable performance.
Using different types of proxies (residential, elite proxy, datacenter, mobile) reduces the risk of detection. Websites are more likely to block data center proxies than residential proxies, so mixing proxy types from various proxy providers ensures greater success.
Always check a website’s robots.txt file to see if scraping is allowed. Overloading a server with requests can lead to IP bans and even legal consequences. Keeping scraping ethical ensures long-term sustainability.
Effective proxy rotation is more than just switching IPs - it requires smart scraping techniques, including delays, CAPTCHA handling, and user agent rotation. By following these best practices, you can ensure smooth and uninterrupted scraping while keeping your scrapers under the radar.
Proxy rotation is an essential technique for efficient and undetectable web scraping. By dynamically switching between multiple IP addresses, you can avoid bans, maintain anonymity, and ensure uninterrupted data extraction. In this guide, we explored the fundamentals of IP rotation, various methods to rotate proxies in Python, and best practices to optimize performance.
To get started, install the right libraries, test your requests without proxies, and gradually implement proxy rotation using a proxy list or proxy rotator. Whether you're using synchronous requests or asynchronous methods like aiohttp, handling multiple requests with proper delays and user-agent rotation is crucial for staying under the radar.
By following these techniques and best practices, you can build a robust scraping setup that effectively bypasses restrictions while ensuring stable and reliable connections. Now, it's time to put these strategies into action and enhance your scraping capabilities!
Tired of getting blocked while scraping? Upgrade your setup with Proxy-Cheap’s high-quality rotating proxies and enjoy seamless data extraction without interruptions.
Get access to a global proxy network and keep your scraping operations running smoothly.